
Teleforking a process onto a different computer!
One day a coworker mentioned that he was thinking about APIs for distributed compute clusters and I jokingly responded “clearly the ideal API would be simply calling telefork() and your process wakes up on every machine of the cluster with the return value being the instance ID”. I ended up captivated by this idea: I couldn’t get over how it was clearly silly, yet way easier than any remote job API I’d seen, and also seemingly not a thing computers could do. I also kind of knew how I could do it, and I already had a good name which is the hardest part of any project, so I got to work.
In one weekend I had a basic prototype, and in another weekend I had a demo where I could telefork a process to a giant VM in the cloud, run a path tracing render job on lots of cores, then telefork the process back, all wrapped in a simple API.
Here’s a video of it running a render on a 64 core cloud VM in 8 seconds (plus 6s each for the telefork there and back). The same render takes 40s running locally in a container on my laptop:
How is it possible to teleport a process? That’s what this article is here to explain! The basic idea is that at a low level a Linux process has only a few different parts, and for each of them you just need a way to retreive it from the donor, stream it over the network, and copy it into the cloned process.
You may be thinking, “but wait, how can you replicate [some reasonable thing like a TCP connection]?” Basically I just don’t replicate tricky things so that I could keep it simple, meaning it’s just a fun tech demo you probably shouldn’t use for anything real. It can still teleport a broad class of mostly computational programs though!
What does it look like
I wrote it as a Rust library but in theory you could wrap it in a C API and then use it via FFI bindings to teleport even a Python process. The implementation is only about 500 lines of code (plus 200 lines of comments) and you use it like this:
use telefork::{telefork, TeleforkLocation};
fn main() {
let args: Vec<String> = std::env::args().collect();
let destination = args.get(1).expect("expected arg: address of teleserver");
let mut stream = std::net::TcpStream::connect(destination).unwrap();
match telefork(&mut stream).unwrap() {
TeleforkLocation::Child(val) => {
println!("I teleported to another computer and was passed {}!", val);
}
TeleforkLocation::Parent => println!("Done sending!"),
};
}
I also provide a helper called yoyo that teleforks to a server, executes a closure you give it, then teleforks back. This provides the illusion that you can easily run a snippet of code on a remote server, perhaps one with much more compute power available.
// load the scene locally, this might require loading local scene files to memory
let scene = create_scene();
let mut backbuffer = vec![Vec3::new(0.0, 0.0, 0.0); width * height];
telefork::yoyo(destination, || {
// do a big ray tracing job on the remote server with many cores!
render_scene(&scene, width, height, &mut backbuffer);
});
// write out the result to the local file system
save_png_file(width, height, &backbuffer);
Anatomy of a Linux process
Let’s look at what a process on Linux (the OS telefork works on) looks like:
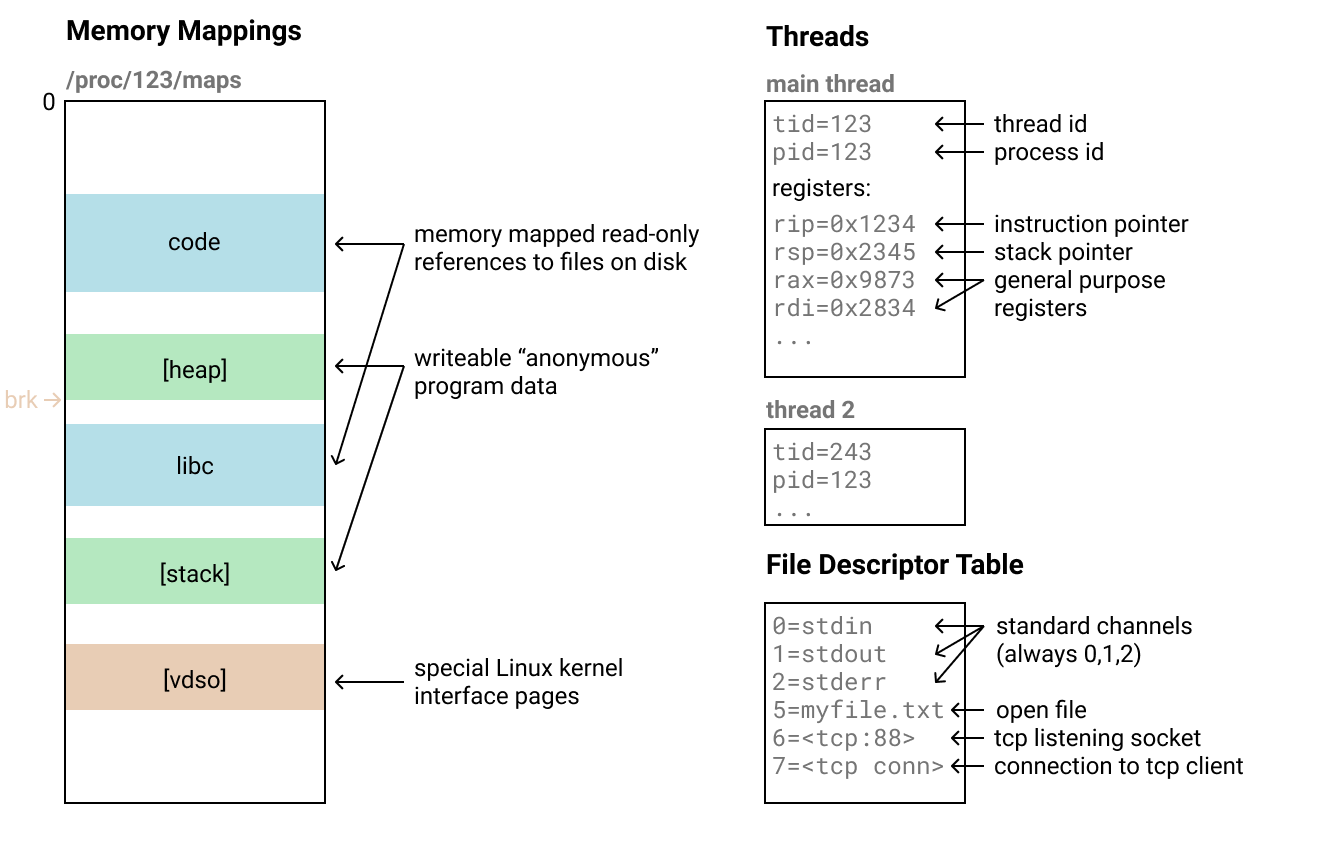
- Memory mappings: These specify the ranges of bytes from the space of possible memory addresess that our program is using, composed of “pages” of 4 kilobytes. You can inspect them for a process using the
/proc/<pid>/mapsfile. These contain both all the executable code of our program as well as the data it is working with.- There are a few different types of these but we can treat these as just ranges of bytes that need to be copied and recreated at the same place (with the exception of some special ones).
- Threads: A process can have multiple threads executing simultaneously on the same memory. These have ids and maybe some other state but when they’re paused they’re mainly described by the registers of the processor corresponding to the point of execution. Once we have all the memory copied we can just copy the register contents over into a thread on the destination process and then resume it.
- File descriptors: The operating system has a table mapping ordinary integers to special kernel resources. You can do things with these resources by passing those integers to syscalls. There are a whole bunch of different types of resources these file descriptors can point to and some of them like TCP connections can be tricky to clone.
- I just gave up on this part and don’t handle them at all. The only ones that work are stdin/stdout/stderr since those are always mapped to 0, 1 and 2 for you.
- That doesn’t mean it’s not possible to handle them, it just would take some extra work I’ll talk about later.
- Miscellaneous: There’s some other miscellaneous pieces of process state that vary in difficulty to replicate and most of the time aren’t important. Examples include the
brkheap pointer. Some of these are only possible to restore using weird tricks or special syscalls likePR_SET_MM_MAPthat were added by other restoration efforts.
So we can make a basic telefork implementation by just figuring out how to recreate the memory mappings and main thread registers. This should handle simple programs that mostly do computation without interacting with OS resources like files (in a way that needs to be teleported, opening a file on one system and closing it before calling telefork is fine).
How to telefork a process
I wasn’t the first to think of the possibility of recreating a process on another machine. I emailed @rocallahan, the author of the rr record and replay debugger to ask some questions since rr does some very similar things to what I wanted to do. He let me know of the existence of CRIU, which is an existing system that can stream a Linux process to a different system, designed for live migrating containers between hosts. CRIU supports restoring all sorts of file descriptors and other state, however the code was really complex and used lots of syscalls that required special kernel builds or root permissions. Linked from the CRIU wiki page I found DMTCP which was built for snapshotting distributed supercomputer jobs so they could be restarted later, and it had easier to follow code.
These didn’t dissuade me from trying to implement my own system since they’re super complex and require special runners and infrastructure, and I wanted to show how simple a basic teleport can be and make it just a library call. So I read pieces of source code from rr, CRIU, DMTCP, and some ptrace examples, and put together my own telefork procedure. My method works in its own way that’s a hodgepodge of different techniques.
In order to teleport a process, there’s both work that needs to be done in the source process which calls telefork, and at the call to the function which receives a streamed process on the server and recreates it from the stream (telepad). These can happen concurrently, but it’s also possible to do all the serializing before loading, for example by dumping to a file then loading later.
Below is a simplified overview of both processes, if you want to know exactly how everything happens I encourage you to read the source. It’s heavily commented, all in one file, and ordered so you can read it top to bottom to understand how everything works.
Sending a process using telefork
The telefork function is given a writeable stream over which it sends all the state of its process.
- Fork the process into a frozen child. It can be hard for a process to inspect its own state since as it inspects the state things like the stack and registers change. We can avoid this by using a normal Unix
forkand then have the child stop itself so we can inspect it. - Inspect the memory mappings. This can be done by parsing
/proc/<pid>/mapsto find out where all the memory maps are. I used the proc_maps crate for this. - Send the info for special kernel maps. Based on what DMTCP does, instead of copying the contents of special kernel maps we remap them, and this is best done before the rest of the mapping so we stream them first without their contents. These special maps like
[vdso]are used to make certain syscalls like getting the time faster. - Loop over the other memory maps and stream them to the provided pipe. I first serialize a structure containing info about the mapping and then I loop over the pages in it and use the
process_vm_readvsyscall to copy memory from the child to a buffer, then write that buffer to the channel. - Send the registers. I use the
PTRACE_GETREGSoption for theptracesyscall, which allows me to get all register values of the child process. Then I just write them in a message over the pipe.
Running syscalls in a child process
In order to mold a target process into a copy of the incoming process we’ll need to get the process to execute a bunch of syscalls on itself without having access to any code, because we’ve deleted it all. Here’s how I do remote syscalls using ptrace, which is a versatile syscall for manipulating and inspecting other processes:
- Find a syscall instruction. You need at least one syscall instruction for the child to execute to be in an executable mapping. Some people patch one in, but instead I use
process_vm_readvto read the first page of the kernel[vdso]mapping, which as far as I know contains at least one syscall in all Linux versions so far, and then search through the bytes for its offset. I only do this once and update it when I move the[vdso]mapping. - Set up the registers to execute a syscall using
PTRACE_SETREGS. The instruction pointer points to the syscall instruction,raxholds the Linux syscall number, andrdi, rsi, rdx, r10, r8, r9hold the arguments. - Step the process one instruction using the
PTRACE_SINGLESTEPoption to execute the syscall instruction. - Read the registers using
PTRACE_GETREGSto retreive the syscall return value and see if it succeeded.
Receiving a process using telepad
Using this primitive and ones I’ve already described we can recreate the process:
- Fork a frozen child. Similar to sending except this time we need a child process we can manipulate to turn it into a clone of the process being streamed in.
- Inspect the memory mappings. This time we need to know all the existing memory maps so we can remove them to make room for the incoming process.
- Unmap the existing mappings. We loop over each of the mappings and manipulate the child process into calling
munmapon them. - Remap the special kernel mappings. Read their destinations from the stream and use
mremapto remap them to their target destination. - Stream in the new mappings. Use remote
mmapto create the mappings, thenprocess_vm_writevto stream memory pages into them. - Restore the registers. Use
PTRACE_SETREGSto restore the registers for the main thread that were sent over, with the exception ofraxwhich is the return value for theraise(SIGSTOP)that the snapshotted process stopped on, which we overwrite with an arbitrary integer passed totelepad.- The arbitrary value is used so the telefork server can pass the file descriptor of the TCP connection the process came in on, so that it can send data back, or in the case of
yoyoexecute ateleforkback over the same connection.
- The arbitrary value is used so the telefork server can pass the file descriptor of the TCP connection the process came in on, so that it can send data back, or in the case of
- Restart the process with its brand new contents by using
PTRACE_DETACH.
Doing more things properly
There’s a few things that are still broken in my implementation of telefork. I know how to fix them all, but I’m satisfied with how much I’ve implemented and sometimes they’re tricky to fix. This describes a few interesting examples of those things:
- Handling the vDSO properly. I
mremapthe vDSO in the same way that DMTCP does but that turns out to work only when restoring on the exact same kernel build. Copying the vDSO contents instead can work accross different builds of the same version, which is how I got my path tracing demo to work since getting the number of CPU cores in glibc checks the current time using the vDSO in order to cache the count. However the way to actually do it properly is to either patch all the vDSO functions to just execute syscall instructions likerrdoes, or to patch each vDSO function to jump to the vDSO function from the donor process. - Restoring
brkand other miscellaneous state. I tried to use a method from DMTCP to restore thebrkpointer but it only works if the targetbrkis greater than the donor’sbrk. The correct way to do it that also restores other things isPR_SET_MM_MAP, but that requires elevated permissions and a kernel build flag. - Restoring thread local storage. Thread local storage in Rust seems to just work™ presumably because the FS and GS registers are restored, but there’s apparently some kind of
glibccache of the pid and tid that might mess up a different kind of thread local storage. One solution CRIU can do using fancy namespaces is restore the process with the same PID and TIDs. - Restore some file descriptors. This could be done either using individual strategies for each type of file descriptor, like checking if a file with the same name/contents exists on the destination system, or forwarding all reads/writes to the process source system using FUSE. However it’s a ton of effort to support all the types of file descriptors, like running TCP connections, so DMTCP and CRIU just painstakingly implement the most common types and give up on things like
perf_event_openhandles. - Handling multiple threads. Normal Unix
fork()doesn’t do this, but it should just involve stopping all threads before the memory streaming, then copying their registers and reinstating them in threads in the cloned process.
Even crazier ideas
I think this shows that some crazy things you might have thought weren’t possible can in fact be done given the right low level interfaces. Here’s some ideas extending on the basic telefork ideas that are totally possible to implement, although perhaps only with a very new or patched kernel:
- Cluster telefork. The original inspiration for telefork was the idea of streaming a process onto every machine in a compute cluster. You could maybe even use UDP multicast or peer-to-peer techniques to make the distribution of memory to the whole cluster faster. You probably also want to provide communication primitives.
- Lazy memory streaming. CRIU submitted patches to the kernel to add something called
userfaultfdthat can catch page faults and map in new pages more efficiently thanSIGSEGVhandlers andmmap. This can let you stream in new pages of memory only as they are accessed by the program, allowing you to teleport processes with lower latency since they can start running basically right away. - Remote threads! You could transparently make a process think it was running on a machine with a thousand cores. You could use
userfaultfdplus a patch set for userfaultfd write protection which was just merged earlier this month to implement a cache-coherency algorithm like MESI to replicate the process memory across a cluster of machines efficiently such that memory would only need to be transferred when one machine read a page another wrote to since its last read. Then threads are just sets of registers that are very cheap to distribute across machines by swapping them into the registers of pools of kernel threads, and intelligently rearrange so they’re on the same machine as other threads they communicate with. You could even make syscalls work by pausing on syscall instructions, transferring the thread to the original host machine, executing the syscall, then transferring back. This is basically the way your multi-core or multi-socket CPU works except using pages instead of cache lines and the network instead of buses. The same techniques like minimizing sharing between threads that work for multi-core programming would make programs run efficiently here. I think this could actually be very cool, although it might need more kernel support to work seamlessly, but it could allow you to program a distributed cluster the same way you program a many-core machine and (with a bunch of optimization tricks I haven’t yet written about) have it be competitively efficient with the distributed system you otherwise would have written.
Conclusion
I think this stuff is really cool because it’s an instance of one of my favourite techniques, which is diving in to find a lesser-known layer of abstraction that makes something that seems nigh-impossible actually not that much work. Teleporting a computation may seem impossible, or like it would require techniques like serializing all your state, copying a binary executable to the remote machine, and running it there with special command line flags to reload the state. But underneath your favourite programming language there’s a layer of abstraction where you can choose a fairly simple subset of things that make it possible to teleport at least most pure computations in any language in 500 lines of code and a single weekend. I think this kind of diving down often leads to solutions that are simpler and more universal. Another one of my projects like this is Numderline.
Of course, they often seem like extremely cursed hacks and to a large extent they are. They do things in a way nobody expects, and when they break they break at a layer of abstraction they aren’t supposed to break at, like your file descriptors mysteriously dissapearing. Sometimes though you can hit the layer of abstraction just right and handle all the cases such that everything is seamless and magic, I think good examples of this are rr (although telefork manages to be cursed enough to segfault it) and cloud VM live migration (basically telefork at the hypervisor layer).
I also like thinking about these things as inspiration for alternative ways computer systems could work. Why are our cluster computing APIs so much more difficult to use than just running a program that broadcasts functions to the cluster? Why is networked systems programming so much harder than multithreaded programming? Sure you can give all sorts of good reasons, but they’re mostly based on how difficult it would be given how other existing systems work. Maybe with the right abstraction or with enough effort a project could seamlessly make it work, it seems fundamentally possible.
