
Implicit In-order Forests: Zooming a billion trace events at 60fps
In the course of trying to figure out how to smoothly zoom timelines of a billion trace events, I figured out a cool tree structure that I can’t find elsewhere online, which it turned out two of my friends have independently derived after not finding anything on their own searches. It’s a way of implementing an index for doing range aggregations on an array (e.g “find the sum/max of elements [7,12]”) in O(log N) time, with amortized constant time appends, a simple implementation (around 50 lines of Rust), low constant factors, and low memory overhead.
The structure is a variation on the idea of an implicit binary tree, usually used for heaps, which let you represent a complete binary tree compactly in an array, with structure determined by layout of the array rather than pointers. Instead of arranging nodes breadth-first like usual, the structure I use has an in-order depth-first arrangement, and it uses a forest of power-of-two sized complete trees instead of one nearly-complete tree. These changes make the implementation of appends much simpler, improve cache efficiency, lower memory overhead, and if combined with a virtual-memory-based growable array provide O(log N) tail latency on appends instead of O(N).
I used my implementation to make a prototype trace timeline that can smoothly zoom 1 billion events, which I don’t think any existing trace viewer can do while preserving similar detail, but the underlying structure can aggregate any associative operation (monoid). While my high-level competitve programmer friends didn’t recognize the layout, my friend Raph Levien remembered figuring out a similar thing for Android’s SpannableStringBuilder, and my colleague Stephen Dolan said he went on a similar journey of discovery while coming up with vectorization-friendly k-d trees.
The IForestIndex data structure
The general idea behind data structures to accelerate range queries is that pre-aggregating elements into chunks of varying sizes can save work at query-time. When we get the range we want to query, we pick the set of chunks that together make up the range and aggregate them together, as opposed to aggregating all the individual elements in the range. A binary segment tree structure where the lowest level aggregates two elements, the next aggregates four elements and so on leads to a guarantee that any range can be covered with O(log N) chunks.
What I’ll describe is a specific way to lay out such an aggregation structure in an array, take a glance and I’ll explain the diagram’s details below:
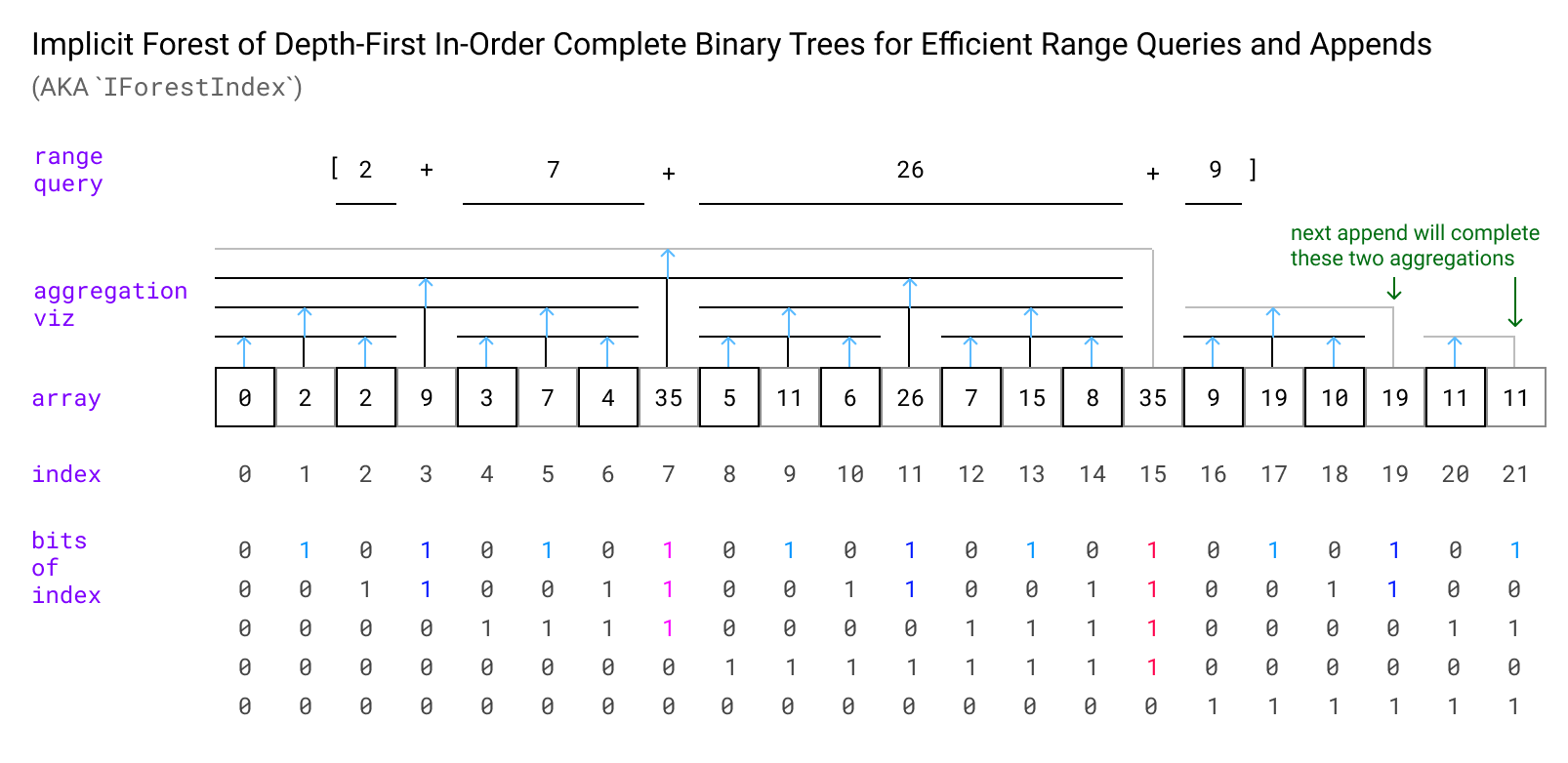
The in-order layout is a way to store an aggregation tree in an array where every even indexed element is a leaf and every odd indexed element aggregates to its left and right using some associative operation (the diagram uses sum). The aggregating nodes form a binary tree structure such that the first level aggregates two leaf nodes, the second level aggregates two level one aggregation nodes, etc…
When our number of items isn’t a power of two, some of the aggregation nodes at higher levels won’t be able to aggregate as far to the right as they’re supposed to, because there isn’t a node there yet, so they’ll be incomplete (shown in grey in the diagram). This means it isn’t technically a tree structure, but a forest of power-of-two sized trees, making up the correct number of total items. When we append a new item, we first append the leaf node, then complete any incomplete trees that should include that node, and then add a new incomplete aggregation node of the right height after it.
How do we decide which level a given node should aggregate and where the incomplete nodes it should complete are? It turns out that with this layout, the level of an aggregation node corresponds exactly to the number of trailing one bits in the binary representation of the index! This is great because modern processors have an efficient single instruction for “count trailing zeros”, and trailing ones just requires a bitwise not before that. It also turns out that the nodes we need to aggregate are powers of two away, and the number of aggregation nodes to complete corresponds to the level of the new aggregation node. This leads to a very simple implementation:
impl<A: Aggregate> IForestIndex<A> {
// ...
pub fn push(&mut self, block: &TraceBlock) {
self.vals.push(A::from_block(block));
let len = self.vals.len();
// We want to index the first level every 2 nodes, 2nd level every 4 nodes...
// This happens to correspond to the number of trailing ones in the index
let levels_to_index = len.trailing_ones()-1;
// Complete unfinished aggregation nodes which are now ready
let mut cur = len-1; // The leaf we just pushed
for level in 0..levels_to_index {
let prev_higher_level = cur-(1 << level); // nodes at a level reach 2^level
let combined = A::combine(&self.vals[prev_higher_level], &self.vals[cur]);
self.vals[prev_higher_level] = combined;
cur = prev_higher_level;
}
// Push new aggregation node going back one level further than we aggregated
self.vals.push(self.vals[len-(1 << levels_to_index)].clone());
}
// ...
}
The range query is more straightforward in that it’s just starting on the left of the range and then skipping forward using the longest-reaching aggregation node it can without overshooting. I’ll let the code (and the example at the top of the diagram) speak for itself:
pub fn range_query(&self, r: Range<usize>) -> A {
fn left_child_at(node: usize, level: usize) -> bool {
// every even power of two block at each level is on the left
(node>>level)&1 == 0
}
fn skip(level: usize) -> usize {
// lvl 0 skips self and agg node next to it, steps up by powers of 2
2<<level
}
fn agg_node(node: usize, level: usize) -> usize {
node+(1<<level)-1 // lvl 0 is us+0, lvl 1 is us+1, steps by power of 2
}
let mut ri = (r.start*2)..(r.end*2); // translate underlying to interior indices
let len = self.vals.len();
assert!(ri.start <= len && ri.end <= len,
"range {:?} not inside 0..{}", r, len/2);
let mut combined = A::empty();
while ri.start < ri.end {
// Skip via the highest level where we're on the left and it isn't too far
let mut up_level = 1;
while left_child_at(ri.start, up_level) && ri.start+skip(up_level)<=ri.end {
up_level += 1;
}
let level = up_level - 1;
combined = A::combine(&combined, &self.vals[agg_node(ri.start, level)]);
ri.start += skip(level);
}
combined
}
Edit: Michael Rojas wrote a Typescript implementation that includes more operations (like in-place update), as well as more bit tricks for improved efficiency. I updated the range query in my repo based on his work.
What’s good about this layout
The closest alternative to this layout is the breadth-first layout described everywhere else online, where you put the root node first, then all the nodes of the next level, and so on until at the end you have all the leaf nodes, with some spots at the end unfilled because you need to round the tree size up to the next power of two. Both of these layouts have nice mathematical relations that enable traversing the tree and mapping between leaf node indices and an array storing the data you’re indexing.
Edit: nightcracker on Reddit points out that it’s possible to formulate implicit Fenwick trees for arbitrary range queries with efficient append and a terse implementation. It looks like they have 3N size overhead instead of 2N, and I haven’t investigated enough to speak to other cache or efficiency properties.
Avoiding the memory and tail latency of amortized resizing
The main reason I ended up looking for an alternative to the breadth-first layout is that breadth-first append is annoying to implement. Because it’s a single incomplete tree rather than a forest of complete trees, whenever the size crosses a power of two you need to rearrange everything into a bigger tree structure with one more level. Not only do you need to write code to implement this case but the newly re-allocated tree has a 4x memory overhead over the space required for just the leaf nodes: 2x for being half empty and 2x for the usual cumulative count of all the aggregation nodes. Then if you don’t implement a fancy in-place re-organize, memory peaks at 6x since you need to have both the old and new tree around while you move things. Even if your amortized append cost is still O(1), the tail latency is terrible.
But wait, in my implementation of the in-order layout I use Rust’s growable Vec, and doesn’t that have the same 2x amortized resizing space waste and tail latency issues behind the scenes? Yes, kind of: In the basic case all I’m saving is implementation complexity, but there’s a way to improve the implementation to avoid this. Because 64 bit computers have address spaces way bigger than their physical memories, it’s possible to reserve an enormous address range for an array and then only allocate real pages at the end (which take up physical memory) as the array is filled. This avoids any slow resizing case and makes space waste only a small constant. If you want this to work on Windows, it requires a special implementation, but on Linux and macOS all you need to do is construct your Vec by using Vec::with_capacity with a huge size that’s more than you’ll need and smaller than physical memory, and VM overcommit will promise you the full address range and only use more physical memory as you push to the vector. I was thinking about how this data structure could be used for indexing enormous traces by using most of the memory on a machine, so the fact that this technique allows making the most of memory without much implementation effort was a big win.
You can apply the same technique for some savings on the breadth-first order, but because the aggregation nodes for the unusued space are not all at the end of the array you’d need to support missing pages in the middle of your array. You’d also still need to implement an in-place tree reorganize, so it would be much more complicated and you still wouldn’t get the tail latency benefits.
Better cache coherency
The depth-first layout has a nice property that near the leaves, entire subtrees are grouped together in memory, meaning subtrees may all be in the same cache line or page. This is especially nice given that range queries can traverse the tree from the bottom up and then down, avoiding touching unnecessary higher levels that are further away. In contrast for a tree in breadth-first order, the next level up will be in a separate range of memory from its leaves. On a huge tree where each parent node may end up on a separate page this may cause lots of TLB misses. This might’ve been bad for a case like my trace visualization, which requires thousands of queries per second on relatively small ranges in a huge structure.
The cache efficiency is likely still not as good as a B-tree or Van-Emde-Boas (VEB) layout, but those are much more complicated to implement. For VEB layouts, I could find research papers and benchmarks that describe the mathematical structure of the layout, but not how to efficiently implement operations like append. The usual breadth first order is also better at keeping all the higher levels of the tree together, so might perform better for repeated traversals from the root, I’m not sure.
Simpler and more memory-efficient than non-implicit structures
I’ve mainly compared against breadth-first implicit binary trees because they’re the closest competitor, but I started out looking at other structures. I knew about the general idea of segment trees and they’re often implemented as standard non-implicit tree structures. I first embarked on writing a B-tree structure but got frustrated with how much code it was taking and the different cases where non-leaf nodes contained pointers but leaves didn’t. I thought a lot about other data structures like skip lists and various optimizations of them but they were still too complex. The non-implicit data structures also tended to introduce a lot of memory overhead via their node pointers.
Other nice properties
In addition to appending, it’s possible to do some other operations like updating the values of nodes in place (Raph’s SpannableStringBuilder does this). If you’re building an entire tree at once instead of incrementally appending it’s possible to parallelize the construction of the index by divvying up subtrees among threads. I figured out but never used the fact that if you want to search a forest from the top down then checking the largest/first tree and working down has binary-search-like efficiency properties since the power-of-two structure means all the further trees together can be at most half the remaining items. Within each tree, my colleage Stephen pointed out that if you want to traverse the tree down to an index, then iterating the bits of the index in reverse tells you the direction to recurse at each level.
Backstory: Rendering huge traces
So how did I end up investigating this and what’s the connection to trace viewers? I was trying out Tracy, a system for doing performance optimization by capturing tracing events from instrumentation in your code and displaying it on a slick timeline UI, and I noticed that when I zoomed out enough all the detail was replaced with a squiggle that signified “some events here”. I’d used Perfetto and Catapult (other trace viewers, both by Google) before and they continued to show the texture of my trace events when zoomed out, but became very slow on large traces. I’ve never used RAD Telemetry but it looks like it’s somewhere in between, where unlike Tracy it still shows the number of levels but loses all other information when zoomed out.
Edit: Per Vognesen on Twitter says Telemetry does have a range aggregation data structure, which I’m guessing they use for aggregating time summary information panels (since their zoomed out rendering looks different than Perfetto). He links an interesting HN comment of his discussing a design using a hierarchy of B+ trees.
I checked Perfetto’s source code and found that it was quantizing the trace into small time slices and displaying color of the longest trace span under each time slice at each level. Combined with Perfetto’s approach of coloring trace spans based on a hash of the label, I thought this was a good way to give an overview of a zoomed out trace. It tended to show what the dominant event was at each level, how deep the nesting was at different points, and clicking showed what that specific event color was.
The problem is that Perfetto’s implementation used a slow linear scan and so when zoomed out on a large trace was very slow, and they relied on asynchrony to keep the UI responsive while the next zoom level was being computed. Since the “longest span in a time slice” corresponded to a range aggregation of “maximum duration” I thought it should be possible to use a tree structure to accelerate this and find the longest span under every pixel for every track of a large trace at 60fps, since that would only be on the order of 10k O(log N) queries per frame, and it could be parallelized across tracks.
I then embarked on my journey figuring out the IForestIndex data structure, and afterwards I used it to put together a simple proof-of-concept skeleton of a trace viewer
that can smoothly zoom a trace of 1 billion randomly generated events. It’s not pretty since the randomly generated data has no structure, the colors are bad, it doesn’t render any span labels, and I don’t step backwards to render spans that start before the viewport starts, but it works:
I don’t actually plan on implementing my own full trace viewer, it’s a big task. I just wanted to have fun figuring out how to achieve the kind of trace zooming I wanted, and figure out a cool data structure in the process, since I suspected it was possible but didn’t know of anyone who’d done it. Given that I’m one of three people I know who’ve had to figure out this data structure themselves, hopefully this post will help any future people who want a data structure for this kind of problem.
